



|

(Reproduced with kind permision of Wrox Press: https://www.wrox.com) XSLTIn chapter 2 we saw how we can specify the XML format that our application can work with using validation rules. When we want to exchange information with other applications, it would be nice if everyone would use the same document types (that is use the same validation rules). However, it is inevitable that, for comparable types of data, several document types will emerge. Some repositories will emerge, where schemas and DTDs can be stored and shared. Often these are industry-wide initiatives. However, several schemas for the same data will exist. Therefore, it would be very handy to have a tool or tools to convert a document from one schema to another. These would consist of a set of rules that describe exactly how and where a piece of content in document type A should appear in document type B. These rules might as well be described in XML themselves. This is exactly what XSLT is – a language to specify how to transform an XML document of one type to another document type. To be completely honest with you,
when the XSLT initiative was started, this was not the goal. Back then it was
called XSL (eXtensible Stylesheet Language) and its target was to convert an
XML document to HTML. The specification was divided into two parts: the transformation part (which became XSLT) and the formatting objects part (XSL-FO). This
decision was made because the development of the two parts of the XSL
specification happened at different rates. Indeed, XSLT has recently become
recommended, though XSL-FO is still in the early stages of development. In
addition, the XSL query language, included in the earlier XSL specification,
was removed and combined with the path syntax in XPointer to form XPath. So we have are two
recommendations: XPath and XSLT, and some specifications that will still
undergo serious changes. As XSL-FO is still so premature, it will not be
covered in this book. When the work was in progress, the
editors started to understand that the fields of application of their work were
much broader than just creating HTML. This is still one of the purposes of
XSLT, but only one of many. In the remainder of this chapter we will focus on
the broader possibilities XSLT, and will show how to use it for HTML generation
at the end of the chapter. How Transformation WorksTransforming an XML document from
one format into another always involves three documents: the source document, the destination document and the document holding the transformation
rules, the XSLT stylesheet: 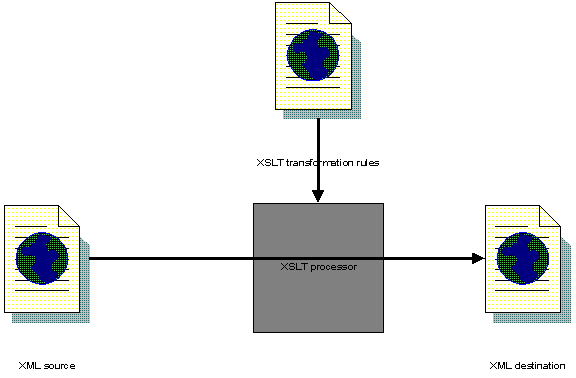 Each stylesheet in XSLT consists of a number of templates. A template
defines how a certain kind of content in the source document appears in the
destination document. A template always has an XPath expression that describes
what nodes in the source the template applies to.
Most programming languages start their
execution at a specific place in the program code (in Visual Basic, this is Sub
Main()). XSLT is different. It starts with the
data and searches for the right code to execute with that data. When a document
is transformed with an XSLT stylesheet, the start node is the document root. Now
the following steps will be taken: 1.
The processor searches for the most suitable template
in the stylesheet for transforming this node. (We'll talk about what makes a
template suitable later). 2.
This template defines certain output nodes, which
are added to the result document. 3.
The template can also specify which nodes should be
processed next. For all of these nodes, go to step 1. The process ends when no more
nodes are specified to process next. The most common form is that every
template tells the processor to continue by processing the children of the
current node. This makes sure that all nodes will get processed and that no
infinite loops can occur. Programming stylesheets is an art
of its own and the very recursive nature of the task will sometimes puzzle the
average VB programmer. It can help to think of a template as an event handler.
At the start of the transformation, the event for processing the root is
raised. The processor selects the best handler and executes this. This event
handler produces nodes in the output document, but can also raise events
itself. For all of these raised events, the XSLT processor will again search in
the stylesheet for handlers, etc… Before we look at writing
stylesheets, let's take a look at the other requirement for transformations –
XSLT processors. Some Good XSLT ProcessorsAt the time of writing, the XSLT specification was still very fresh, so implementations of the full specification were still scarce. The best one at the time was SAXON (at least the best implementation that I could find). SAXON is implemented in Java, with source code available, but also a Win32 binary can be downloaded (https://users.iclway.co.uk/mhkay/saxon/). This can be called as follows: saxon –o destination.xml source.xml stylesheet.xsl Another well-known implementation is XT by James Clark. Clark was one of the main contributors to the XSLT specification and has always tried to keep his implementation following the specification as close as possible. At the time of writing there were still a few features unimplemented in XT, but a full version will undoubtedly be released (download from www.jclark.com/xml/xt.html). Like SAXON, XT is distributed as Java classes and code, but can also be downloaded in binary form, allowing use like this: xt source.xml stylesheet.xsl destination.xml The third implementation that should be mentioned in a book for VB programmers is the Microsoft MSXML library. The version available at the time of writing was dated March 1999, and is therefore rather out-of-date. Microsoft has promised though that the full specification will be included in a next release. The fact that these libraries can be used as COM objects from VB code or scripting gives them a huge advantage over the command-line based competition. The performance of the MSXML library is much better than that of the Java-based implementations at the moment, but of course, implementations with different functionality are hard to compare. To give developers a head start when the newer library is
released, Microsoft has published a 'developers preview' in January 2000 (this
is the same preview that was mentioned when we discussed XPath). This preview
can be used side by side with the older library and partially implements the
final specification of XSLT. (Check the appendix to see exactly which parts are
implemented). With the MSXML library, you could do
something like: Dim oDoc as new DOMDocument Dim oXSLT as new DOMDocument oDoc.async = false oXSLT.async = false oDoc.load “https://www.comp.com/sourceDocument.xml" oXSLT.load “https://www.comp.com/stylesheet.xsl" sResult = oDoc.transformNode(oXSLT) The transformNode method returns a string holding the full transformed document. The current version of MSXML can be downloaded from https://msdn.microsoft.com/downloads/tools/xmlparser/xmlredist.exe, and the developer's preview from https://msdn.microsoft.com/downloads/webtechnology/xml/msxml.asp. XSLT Elements – Composing the XSLT StylesheetAn XSLT document defines rules for transforming a specific kind of XML document into another kind of document. These rules are themselves defined in an XML-based document syntax. Most of this chapter will be used to describe all of the available elements in an XSLT document. To differentiate the XSLT-specific elements in a stylesheet from other XML content, XSLT uses namespaces. The official XSLT namespace is https://www.w3.org/1999/XSL/Transform. Remember that this URI does not necessarily point to any resource. It only specifies to the XSLT processor that these elements are part of an XSLT stylesheet. In this chapter we will always use the xsl namespace prefix for XSLT elements. This assumes that all our stylesheets contain this namespace declaration: xmlns:xsl="https://www.w3.org/1999/XSL/Transform" For example, if we talk about the template element in the XSLT namespace, we will display it as xsl:template. Remember that this URL is not pointing to anything special. It is only used as a unique identifier to make these elements unique from all other kinds of elements (that are not specifying an XSLT stylesheet). stylesheetThe root element of any XSLT stylesheet document is normally the stylesheet element (exceptions are the transform element and the simplified syntax; both will be explained later). It holds a number of templates and can hold some more elements that specify settings. Elements that can appear in the stylesheet element (and only there) are called top level elements. An example of a stylesheet element is shown: <xsl:stylesheet id = id
extension-element-prefixes = tokens exclude-result-prefixes = tokens version = number> </xsl:stylesheet> The version attribute of the stylesheet element is necessary to ensure that later additions to the XSLT specification can be implemented without changing the old stylesheets. The current version is 1.0. When newer versions of the recommendation are specified, the version number can be increased (but the namespace for XSLT will remain stable, including the '1999'). If the version is set to anything higher than 1.0, this will also affect the way a 1.0 processor works. The processor will switch on forward compatibility mode. In this mode, the processor ignores any unknown elements or elements in unexpected places. You will rarely use the other attributes of the stylesheet element, but we'll discuss them here briefly anyway. With the extension-element-prefixes attribute, it is possible to assign a number of namespace prefixes, other than the defined XSLT prefix, as XSLT extension prefixes. This tells the XSLT processors that support any extensions to watch out for these namespace extensions. They might be extensions that it knows. The prefixes must be defined namespaces. If the source document contains namespace declarations, these will normally automatically appear in the result document as well. The only exception is the XSLT declaration itself. If there are any other namespaces in the source document that you do not want to show up in the output, these can be excluded with the exclude-result-prefixes attribute. Just to give you the idea, we'll have a look at an extremely simple stylesheet here. We'll use some elements that we have not described yet, but we'll describe what happens afterwards. <?xml version="1.0"?> <xsl:stylesheet xmlns:xsl=" https://www.w3.org/1999/XSL/Transform" version="1.0"> <xsl:template match="/"> <root_node/> </xsl:template> </xsl:stylesheet> You will recognize the stylesheet element carrying the namespace declaration to indicate that this is an XSLT stylesheet. Inside the stylesheet is one xsl:template element. This element has a match attribute set to "/" and a child element root_node. This template matches ('is a suitable template for') the document root (indicated by '/'). The only content of the template is the root_node element. This is not an XSLT element, but a literal element that is added to the output when this template is executed. When this stylesheet is used to transform an arbitrary XML document, the processor will start processing the document root of the source document. It will find a suitable template in the stylesheet (the only template we have) and use it to process the document root. The only thing the template does is create a root_node element in the output document. This stylesheet will transform an arbitrary XML source document to: <root_node/> transformThe transform element is synonymous to the stylesheet element. It is included because the uses for XSLT have grown much wider than just giving style to XML content, but the stylesheet is still the most common way to define a transformation. Functionally, there is no difference. importTo construct a stylesheet from several reusable fragments, the XSLT specification supports the importing of external stylesheet document fragments. This is done with either the import or include elements, for example: <xsl:import
href=uri-reference/ > The document retrieved from the URI should be a stylesheet document itself and the children of the stylesheet element are imported directly into the main stylesheet. The import element can only be used as a top-level element and must appear before any of the template elements in the document. If the XSLT processor is trying to match a node in the source document to a template in the stylesheet, it will first try to use one of the templates in the importing document before trying to use one of the imported templates. This allows for creating rules that are used in many stylesheets. Rules can be overridden by defining one of the rules again locally. Both the import and the include elements may never reference themselves (not even indirectly). includeThe include element is the simpler brother of the import
element: <xsl:include
href=uri-reference /> It just inserts the rules from the referenced URI. These are parsed as if they were in the original document. Like the import element, include can only appear at the top-level. There is no restriction on the location of this element in the document (unlike import). templateThe template element is one of the main building blocks of an XSLT stylesheet. It consists of two parts, the matching pattern and the implementation. Roughly, you can say that the pattern defines which nodes will be acceptable as input for the template. The implementation defines what the output will look like. We will cover the implementation later, when we have discuss the elements that generate output. <xsl:template match = pattern name = qname priority = number mode = qname> <!-- Content: implementation--> </xsl:template> The attributes name, priority and mode are use to differentiate between several templates that match on the same node. In these cases several rules exist for preference of templates over each other. In the section titled "What if Several Templates Match?" we will show the use of these attributes. The match attribute holds the matching pattern for the template. The matching pattern defines for which nodes in the source document this template is the appropriate processing rule. The syntax used is a subset of XPath. It contains only the child and attribute axes (but it is also legal to use "//" from the abbreviated syntax, so the descendant axis is also available). A template matches a node, if the node is part of the result set of the pattern from any available context, which basically says that a node should be "selectable" with the pattern. We'll take a look at a few examples to clear this up. Imagine that we are processing a document with chapters and paragraphs. The paragraphs are marked up with the element para, the chapters with chapter. We will look at possible values for the match attribute of the xsl:template element. This matches any para element that has a chapter element as a parent: <xsl:template match="child::chapter/child::para"> </xsl:template> Note that this will only work when the chapter element has a parent node. This parent node is the context we need to select the para element from with this pattern. Fortunately, all elements have a parent (the root element has the document root for a parent), so this pattern matches all para elements that have a chapter as a parent. This example will match with all para elements: <xsl:template match="para"> </xsl:template> This matches any para element as well as any chapter element: <xsl:template match="(chapter|para)"> </xsl:template> This matches any para element that has a chapter element as an ancestor: <xsl:template match="chapter//para"> </xsl:template> This matches the root node: <xsl:template match="/"> </xsl:template> This matches all nodes but not attributes and the root: <xsl:template match="node()"> </xsl:template> This matches any para element, which is the first para child of its parent: <xsl:template match="para[position() = 1]"> </xsl:template> This matches any title attribute (not an element that has a title attribute): <xsl:template match="@title"> </xsl:template> This matches only the odd-numbered para elements within its parent: <xsl:template match="para[position() mod 2 = 1]"> </xsl:template> Two interesting extra functions that you can use in the pattern are id() and key(). id('someLiteral') evaluates to the node that has 'someLiteral' as its ID value. This pattern matches all para elements that are children of the element with its ID attribute set to 'Table1': <xsl:template match="id('Table1')/para"> </xsl:template> Note that the ID attribute is not necessarily called ID – it can be any attribute that is declared as having type ID in the DTD or Schema. The key() method does something similar, but refers to defined keys instead of elements by ID. Refer to the section covering the xsl:key element to learn more about the key() method. apply-templatesIn the simple and rather non-functional example we looked at in the paragraph about the stylesheet element, we had only one template. This template matched on the document root. When the XSLT processor starts transforming a document with that stylesheet, it will first search for a template to match the document root. Our only template does this, so it is executed. It generates an output element and processing is stopped. All content held by other nodes than the document root is not processed. We need a way to tell the processor to carry on processing another node. <xsl:apply-templates select = node set-expression mode = qname> </xsl:apply-templates> This is done using the xsl:apply-templates element. It selects the nodes that should be processed next using an XPath expression. The nodes in the node set that is selected by this XPath expression will become the new context nodes. For these new context nodes, the processor will search a new matching template. The transformed output of these nodes will appear within the output generated by the current template. You may compare the use of the apply-templates element with calling a subroutine in a procedural programming language. There are only two possible attributes for the apply-templates element: select and mode. The select attribute is the more important one. It specifies which nodes should be transformed now and have their transformed output shown. It holds an XPath expression. The expression is evaluated with the current context node. For each node in the result set, the processor will search for the appropriate template and transform it. The default value for the select attribute is 'child::node()'. This matches all child nodes, but not attributes. Let's make a few changes to our example and use xsl:apply-templates: <?xml version="1.0"?> <xsl:stylesheet xmlns:xsl=" https://www.w3.org/1999/XSL/Transform" version="1.0"> <xsl:template match="/"> <root_node> <xsl:apply-templates/> </root_node> </xsl:template> <xsl:template match="*"> <result_node> <xsl:apply-templates/> </result_node> </xsl:template> </xsl:stylesheet> Now we'll use the following source document to test the transformation: <?xml version="1.0" ?> <FAMILY> <PERSON name="Freddy" /> <PERSON name="Maartje" /> <PERSON name="Gerard"/> <PERSON name="Peter"/> <PET name="Bonzo" type="dog"/> <PET name="Arnie" type="cat"/> </FAMILY> Lets first have a look at the changes in the stylesheet. Something was added to the original template: the root_node element now has a child element: xsl:apply-templates. This means that when the template is executed, the root_node element will still output a root_node element in the output document, but between outputting the start tag and the end tag, it will try to process all nodes that are selected by the xsl:apply-templates element. This element has no select attribute, so that defaults to child::node(), which selects all child nodes of the current context (excluding attributes). Another change is that we added a new template, matching on "*". All it does is generating a result_node element in the output document (which does not mean anything, it is just test output). This node too has an xsl:apply-templates child element. We saved the sample XML source as family.xml and the stylesheet as test.xsl. Then we called the SAXON processor like this: saxon –o destination.xml family.xml test.xsl We'll follow the XSLT processor step-by-step as it creates an output document from the sample source document and our test stylesheet: 1. Try to match the root to one of the templates: the first template matches. 2. Process the implementation of the first template, using the root as the context node. 3. The implementation causes the output of a root_node element to the destination document and tells us to process all the child nodes of the root. These are only the XML declaration (<?xml version="1.0"?>) and the FAMILY element. 4. The XML declaration has no matching template, and will not be processed. The FAMILY element matches the second template. 5. The implementation causes the output of a result_node element to the destination document (as a child of the root_node element) and tells us to process all the child nodes of the FAMILY. These are all PERSON and PET elements. 6. The processor tries to match the PERSON element to one of the templates: the second template matches. 7. The second template generates a result_node element in the output and tells the processor to process the children of the element. It finds no children. 8. Steps 6 and 7 are repeated for all PERSON and PET elements. The result of all this processing looks like this: <root_node> <result_node> <result_node/> <result_node/> <result_node/> <result_node/> <result_node/> <result_node/> </result_node> </root_node> The outer element (root_node) is the transformed result of the document root; the element within the root_node is the transformed result of the FAMILY element in the source. All of the PERSON and PET elements are transformed to the six empty result_node elements. So, what about the mode attribute? We will discuss that in the section "What if Several Templates Match?" Pre-defined TemplatesApart from the templates that you will define and implement, two default templates are provided for free. These templates can be overruled by creating a template that matches the same nodes. We haven't covered the implementation of templates yet, but still it can be instructive to see what real implemented templates look like: <xsl:template match="*|/"> <xsl:apply-templates/> </xsl:template> <xsl:template match="text()|@*"> <xsl:value-of select="."/> </xsl:template> What do we see? There are two templates defined. One matches all elements and the root (*|/). The other one matches both text nodes and all attributes. The implementation of the templates is fairly simple. The first one has only an xsl:apply-templates element. The implementation of the second template uses another element: xsl:value-of. This element generates text output containing the string value of the context node. Now suppose that we would try to transform the sample source document (family.xml) using only the built-in templates. What would happen? The document root would be matched by the first built-in template, matching on "*|/", i.e. any node including the root. The only thing this template does is call xsl:apply-templates with no select attribute. This will cause the processor to process all child nodes (but not attributes). The result of our sample source, transformed by only built-in templates would be an empty document. If it contained any text nodes, these would appear in the output. But although no output appears in the result, all nodes in the document have been processed. This is an important fact. The default templates will process all nodes in the document. If you implement your own template, you will specify specific output for the element you are matching. But if you ever want the children of this element to become the context node, you must also make sure that you pass the context to them. One of the most common mistakes is using a stylesheet like this: <?xml version="1.0"?> <xsl:stylesheet xmlns:xsl="https://www.w3.org/1999/XSL/Transform"> <xsl:template match="/"> <HTML><BODY> </BODY></HTML> </xsl:template> <xsl:template match="*"> <!—some content here --> </xsl:template> </xsl:stylesheet> Note that the first template contains no xsl:apply-templates element. This means that after processing the document root and outputting a document like this: <HTML> <BODY/> </HTML> The processor will stop. The context is not passed to any other node, so the XSLT processor assumes that the job is done. We must change that template to: <xsl:template match="/"> <HTML><BODY> <xsl:apply-templates/> </BODY></HTML> </xsl:template> Forgetting to pass the context from a node to its children is one of the most common mistakes when developing XSLT documents. Of course, you may have good reasons to do it on purpose. Often, you don't want all nodes to appear in the destination document and you may decide not to pass focus to them at all. That's fine, as long as it is a deliberate decision to leave apply-templates out. Elements that Generate Output ElementsThe most easily understandable elements an XSLT document are the literals. They must be any fragment of valid XML and should not be in the XSLT namespace, that is any XML content within the xsl:template element that is not prefixed xsl: is passed on to the result document. The output to the destination document is identical to the literal value in the XSLT document. This can be a piece of text, but also a tree of XML nodes. This template will output a LITERALS element for each PERSON element it is used on (we have actually seen this already in the example for the xsl:template element). If the PERSON element has any child elements or attributes, these will not be included in the destination document. <xsl:template match="PERSON"> <LITERALS/> </xsl:template> Literal values can include both text and XML elements. Other nodes, like comments and processing instructions, cannot be output as literal values. A literal value must always be a well-formed piece of XML. So we cannot generate only an opening tag. This would prevent the XSLT document from being well-formed. value-ofThe value-of element generates the string value of the specified node in the destination document. The select attribute indicates which node's value should be output. It contains an XPath expression that is evaluated in the template's context. For example, this code would generate the text string in the destination document of the value of the name attribute of the matched PERSON element: <xsl:template match="PERSON"> <xsl:value-of select="@name"/> </xsl:template> copyThe copy element creates a node in the destination document with the same node name and node type as the context node. The copy element will not copy any children or attributes of an element. An example of using this element would be: <xsl:template match="PERSON|PET"> <xsl:copy/> </xsl:template> This template will output a PERSON element for each matched PERSON element in the source document and a PET element for each matched PET element in the source document. Any attributes of the copied elements will not show up in the destination document. copy-ofThe copy-of element is used to copy a set of nodes to the destination document. The select attribute can be used to indicate which nodes are to be copied. Unlike the copy element, copy-of will copy all children and all attributes of an element. The copy-of element is very much like the value-of element, except that copy-of does not convert the selected node to a string value and that copy-of will copy all selected nodes, not only the first, for example: <xsl:template match="PERSON"> <xsl:copy> <xsl:copy-of select="@name"/> </xsl:copy> </xsl:template> This template creates a PERSON element for each matched PERSON element in the source document and copies any existing name attribute into it. Note how the copying of the attribute is placed within the copying of the element. <xsl:template match="PERSON"> <xsl:copy-of select="."/> </xsl:template> This template will copy a PERSON element with all its attributes and children (and further descendants) to the destination document for each matched PERSON element in the source. elementThe element element (how meta can you get?) allows us to create elements in the destination document. You must use the name attribute to specify the element name. The namespace of the created element can be set using the optional namespace attribute. If you include a namespace attribute, the XSLT engine may decide to change the prefix you specified in the name attribute. The local name (everything after the colon) will remain intact. <xsl:template match="PERSON"> <xsl:element name="PERSONAL_DATA"/> </xsl:template> This template will produce exactly the same output as the example for literals. You may wonder why you would ever use the element element if you can use literals. The extra value is in the fact that the name and namespace attribute are not normal attributes, but 'attribute value templates'. We will explain about those later. attributeThe attribute element generates attributes in the destination document. It works in the same way as the element element, but inserting attributes is bound to some limitations: q You may not insert an attribute in an element after child elements have been added to that element. q You can only use this in the context of an element. Adding an attribute to a comment node is not allowed. q Within the attribute element, no nodes may be generated other than text nodes. Attribute nodes can not have child nodes. This template will create a species attribute for each matched type attribute, inserting the value of the type attribute in the species attribute: <xsl:template match="@type"> <xsl:attribute name="species"> <xsl:value-of/> </xsl:attribute> </xsl:template> Attribute Value TemplatesThe attribute element is often used to create attributes
in the output that have a calculated name. Because their value is not fixed,
they cannot be specified in a literal element, or can they? XSLT specifies a
special kind of attribute, called attribute value templates. All literal attributes in XSLT are value templates, but
many attributes on predefined XSLT elements are as well. An attribute value
template can contain an expression part that is evaluated before execution of
the element the attribute is in. The expression must be placed in curly braces,
so this code: <LITERAL some="blah{4+5}"/> would create this node in the
output: <LITERAL some="blah9"/> The expression can also be an
XPath expression. Using attribute value templates, the following transformation
can be made much more readable than it is with attribute elements, so this code: <photograph> <url>img/pic.jpg</url> <size width="40"/> </photograph> <xsl:template match="photograph"> <img src="{url}" width="{size/@width}"/> </xsl:template> would create: <img src="img/pic.jpg" width="40"/> You cannot use nested braces. If
you need to specify a {, use a
double brace: {{. Check Appendix D to find
out which attributes can be used as value templates. A Stylesheet ExampleBefore we go on with any theory, we will now have a look at a sample. Remember the two XML documents specifying information about a family? It was the first code sample of Chapter 2. We will create a transformation document to convert documents of type A into documents of type B. To work along and try the result of several elements, you may want to use a tool that allows you to see source, rules and destination documents side by side. Some good commercial tools exist, but we suggest using the free open source tool under development by some members of the VBXML mailing list. It is called XSLTester and can be downloaded from www.vbxml.com. The sample XSL files can be downloaded from the Wrox web site. First we define a template that matches the root of the document and outputs all standard elements: <xsl:template match="/"> <FAMILY> <PERSONS> <xsl:apply-templates select="FAMILY/PERSON"/> </PERSONS> <PETS> <xsl:apply-templates select="FAMILY/PET"/> </PETS> </FAMILY> </xsl:template> The template generates a framework for the document and specifies the places where other content should appear. In this case, it specifies the PERSON and PET elements to appear in two different places. Note how two XPath expressions are used to invoke new transformations to occur. For each of the PERSON elements, we want to do a simple transformation: instead of having the name in a name attribute, it should be the content of the element: <xsl:template match="PERSON"> <PERSON> <xsl:value-of select="@name"/> </PERSON> </xsl:template> The PET element needs a more complex transformation. Like the PERSON element, it has its name attribute transformed into the element content. But the PET element in the source document also has a type attribute. In the destination syntax, this attribute is called species. We achieve this transformation with this template: <xsl:template match="PET"> <PET> <xsl:attribute name="species"> <xsl:value-of select="@type"/> </xsl:attribute> <xsl:value-of select="@name"/> </PET> </xsl:template> There it is – our first complete and functional XSLT document. Using MSXML, we could program a VB application that does this transformation containing code like this: Dim oDocFormatA as new DOMDocument 'Object to hold the format we cannot handle Dim oDocFormatB as new DOMDocument 'Object that holds the format we know Dim oXSLT as new DOMDocument 'Object that holds the XSLT stylesheet oDocFormatA.async = false oXSLT.async = false oDocFormatA.load "D:\sourceDocument.xml" oXSLT.load "D:\stylesheet.xsl" oDocFormatB.loadXML( oDocFormatA.transformNode(oXSLT)) ' Now save this string or process it further textThe text element creates a text node in the destination document, holding the content of the original text element. This can also be achieved using literal text, but the text attribute will also be included if it contains only white space. Including white space is the main reason for using the text element. See the sections on strip-space and preserve-space for more information on white space stripping. So these two templates are functionally identical: <xsl:template match="PERSON"> <xsl:text>A person element found</xsl:text> </xsl:template> <xsl:template match="PERSON"> A person element found </xsl:template> processing-instructionThe processing-instruction element generates a processing instruction in the destination document. The syntax for creating a processing instruction is different from that for elements. So this code: <xsl:processing-instruction name="xml-stylesheet"> href="style.xsl" type="text/xsl" </xsl:processing-instruction> would generate in the destination document: <?xml-stylesheet href="style.xsl" type="text/xsl"?> This would be typical for an XSLT document that is used for pre-processing – specifying the transformation rules for the next step. Look at the very end of this chapter to see what the effect of this processing instruction is. The attributes of the processing instruction (href and type) must be created as a text node instead of attributes. This is because the content of the processing instruction does not necessarily use an XML-based syntax. The name attribute must contain a valid name for a processing instruction. This means that it cannot be 'xml' and therefore cannot be used to generate the XML declaration itself. To learn about how to create XML declarations, see the section on the xsl:output element. It is not allowed to create any node other than a text node within the processing-instruction element. It is also forbidden to create textual content holding the string '?>' – it will be interpreted as the end of the processing instruction. commentThe comment element is the only way to create comments in the destination document – a comment in the source document would be ignored, because will not be parsed anyway. So this code: <xsl:comment>This file was generated using XSLT</xsl:comment> would generate this line in the destination document: <!-- This file was generated using XSLT--> It can of course not have any other content than text nodes. numberThe number element is a special one. It is more or less a numerical conversion tool. It creates a numeric value in the output and has a ton of attributes for specifying which number and format should be output: <xsl:number value = number-expression level = "single" | "multiple" | "any" count = pattern from = pattern format = { string } grouping-separator = { char } grouping-size = { number } /> The simplest way to use the number element is by specifying the numeric value that should be output using the value attribute. The value attribute is evaluated and converted to a number (as if using the number function). This number is rounded to an integer value and converted back to a string value. So this code would output the index number of the context node (relative to its parent) followed by a dot and a space: <xsl:number value="position()" format="1. "/> The attributes of the number element can be separated in two groups: those necessary to calculate the numeric value and those necessary to format the numerical value into a string. Number Calculation ExampleAs we saw earlier, the simplest way to calculate the number that will be output to the destination document is using the value attribute. Any expression that can be converted to a number can be used here. A more complex, but in some cases very powerful, way to calculate the number is using the level, count and from attributes. It is used whenever the value property is not used. We will explain the workings of the number element by example. Imagine an XML document containing the full text of a book. The book is divided into chapters (CH elements), sections (SEC elements) and paragraphs (P elements). Within a paragraph, we want to create a paragraph title, including the chapter number, section number, paragraph number, etc. These numbers are not really content; they follow from the structure of the content. We would really like Chapter 1 to be called 'Introduction', not '1. Introduction'. Still, in the final hardcopy (or web page or Acrobat document etc.) we want the number to show up. So we will let the XSLT processor do the counting and insert the numbering on the fly. This is exactly what the number element is good at. Let's have a look at our book document: 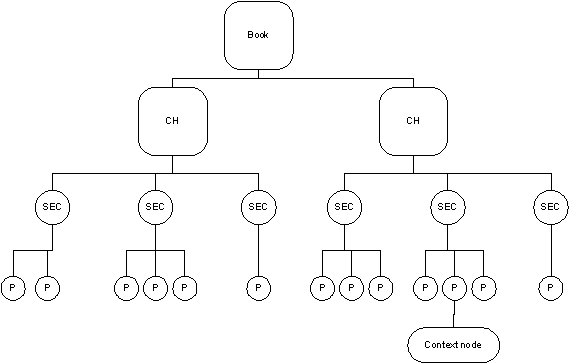 level attributeWe are transforming the context node at the bottom of the diagram. There are three modes for counting nodes, 'single', 'multiple' and 'any'. The counting mode is set using the level attribute. The default mode is 'single'. level='single' The count attribute specifies which kind of nodes you want to count. If the level attribute is set to 'single', the processor will search along the ancestor axis for a node that matches the count attribute. If the count attribute is empty, it uses the context node itself. Once the processor has found a matching ancestor, it counts the number of preceding siblings that also match the count attribute and adds one. It's quite complex, right? Look at the diagram above. Suppose we want to display the paragraph number of the paragraph our context node is part of. That would be 2 – i.e. it is the second paragraph in the section. To display this code would be used: <xsl:number level='single' count='P'/> The processor goes up from the context node until it finds a node that matched 'P'. Then it looks at this node's preceding siblings and counts the number of them that match the count attribute (1). It adds one to that, returning 2. The chapter number would similarly be returned by: <xsl:number level='single' count='CH'/> The from attribute allows us to look only at a part of the ancestor axis. If the from attribute is specified, the processor will first search for an ancestor that matches the from attribute. After that, it will search for the node that will be counted using the count attribute, but it will not look past the node that was matched by the from attribute. This allows you to narrow down the counting to a subtree of the document. Using the 'multiple' mode is very much like the 'single' mode, but it can return more values at once: level='multiple' This is useful for creating paragraph numbers like §2.2.2. The processor will search along the ancestor axis for all nodes matching the count attribute. Each matching node will be used to calculate a number (just like in single mode, counting preceding siblings). A list of numbers is returned, in document order. Therefore this line will return a list with the current chapter number, section number and paragraph number, in that order: <xsl:number level='multiple' count='CH|SEC|P'/> It is up to the number-to-string formatting attributes to output this list as an understandable format. Note that you may run into trouble if your document structure is not as clean as in this sample. If chapters are not siblings of each other, the numbering will go wrong. Also, try to think about what happens if P elements are not only part of SEC elements, but can also appear directly in a CH element. The P elements would become siblings to the SEC elements and be included in the section numbering. If the level attribute is set to 'any', the processor counts all nodes matching the pattern in the count attribute that occur in the document before the context node (including the context node itself and its ancestors): level='any' This can be used for counting the number of a certain kind of node throughout the document (typically 'notes' and 'diagrams'). If the from attribute is specified, the processor searches backward from the context node for the first node matching that specified by the from attribute. Then it counts all nodes matching the count attribute between the 'from node' and the context node. Let's look at a few examples using the document structure from the diagram:
To output numeric values as a string, the number element specifies a set of attributes. We will not cover all details of formatting numeric values here. Numbering is a lot more complicated than you probably think. Ways of numbering include the obvious ones such as Arabic numbers (1, 2, 3, …), letters (a, b, c, …) and Roman numbers (I, II, III, …). But there are many more. Think of all languages using other character sets. Even many languages that use normal Latin characters use other letter orders when counting. Some languages (Hebrew, Greek) have a special non-alphabetic order of letters especially for numbering. While the specification more or less tries to address these issues, in this book we will assume that you want to use one of the numbering types mentioned above, and will refrain from using traditional Georgian numbering! If you need to use more exotic numbering types, check if the XSLT implementation supports them. Most implementations will not. format attributeThe most important attribute for formatting numbers is the format attribute. The format attribute specifies the formatting for a list of numeric values. The format string consists of alphanumeric parts, separated by non-alphanumeric parts. When a list of numbers is formatted, the nth alphanumeric part of the format is used for the nth number. If there are more numbers than formats, the last format is used for the remaining numbers. The default format (to be used if nothing is specified or if the specified format is not supported by the XSLT implementation) is '1'. These are the most common formats:
The non-alphanumeric characters that are used to separate the formats appear in the output separating the formatted numbers. The default separator is the period. Here are some examples (again referring to the previous diagram):
Apart from the format attribute, the number element can carry the grouping-separator and grouping-size attributes. Their use is very simple and we will only show a few examples:
Think about that last one! Of course you would never use this format in real life. If only one of these attributes is specified, then no grouping happens at all. ©1999 Wrox Press Limited, US and UK. |


Contribute to IDR:
To contribute an article to IDR, a click here.
To contact us at IDevResource.com, use our feedback form, or email us. To comment on the site contact our webmaster. |
All content © Copyright 2000 IDevResource.com, Disclaimer notice |




